Downstream Tasks#
Once you have trained a SHRED model, you can use it for various downstream sensing and prediction tasks. The SHREDEngine object provides a convenient interface that wraps your trained SHRED model and DataManager, making it easy to:
encode sensor measurements to latent space
forecast future latent space states
decode latent space back to full-state space
evaluate full-state reconstructions from sensor measurements against the ground-truth
Initialize SHREDEngine#
To initialize SHREDEngine, pass in a DataManager and a trained SHRED model.
from pyshred import SHREDEngine
# Assuming you have a trained SHRED model and DataManager
engine = SHREDEngine(data_manager, trained_shred_model)
Encode sensor measurements to latent space#
The SHREDEngine object provides a .sensor_to_latent() method for generating the latent space associated with the raw sensor measurements.
The raw sensor measurements should have shape (time_steps, num_sensors) and the column order of sensors should match the .sensor_measurements_df attribute in DataManager.
# Raw sensor measurements (e.g., from physical sensors)
sensor_data = your_sensor_measurements # Shape: (time_steps, num_sensors)
# Convert to latent space
latent_representation = engine.sensor_to_latent(sensor_data)
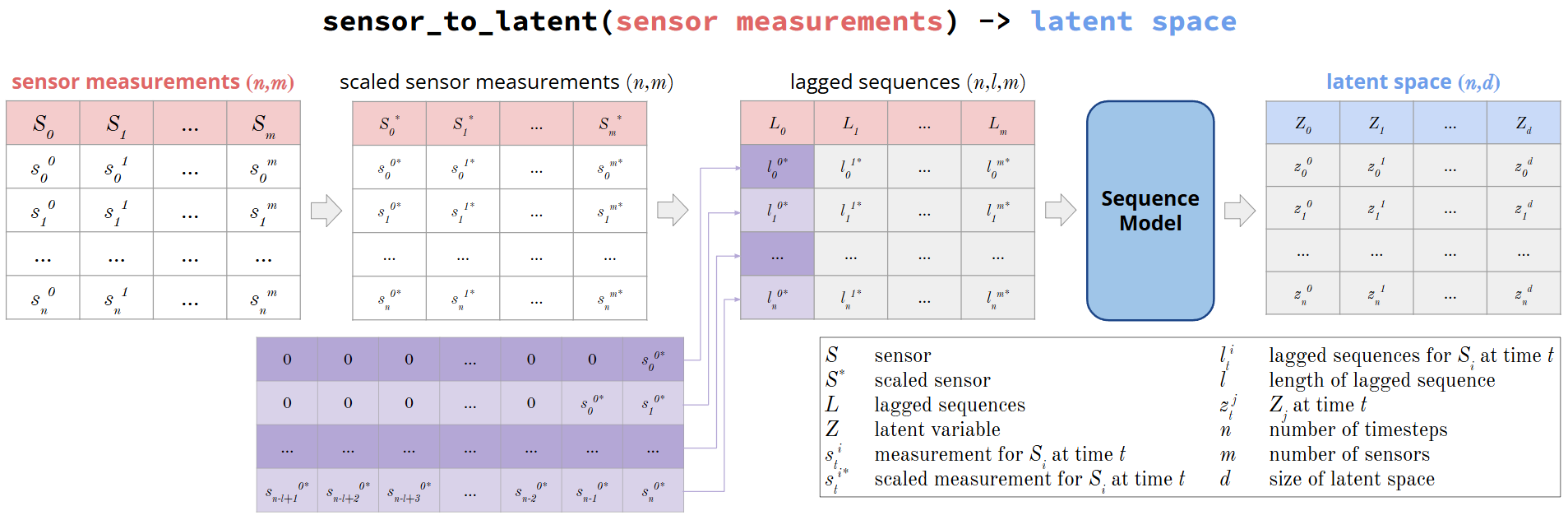
Figure: The sensor_to_latent method takes in raw sensor measurements, scales it, generates lagged sequences of the scaled sensor measurements, then passes it through SHRED’s sequence_model to obtain the latent space associated with the raw sensor measurements.#
Note: the lagged sequences near the start are padded by zeros because there is not enough sensor measurements to look back on.
Forecast future latent space states#
The SHREDEngine provides a .forecast_latent() method that predicts future latent states starting from an initial sequence of latent vectors. This method is available if SHRED’s .latent_forecaster is not None.
# Generate latent states from current sensor measurements
current_latents = engine.sensor_to_latent(sensor_measurements)
# Set forecast horizon (number of steps to predict into the future)
forecast_horizon = 50
# Prepare initial seed for forecasting
seed_length = shred.latent_forecaster.seed_length
init_latents = current_latents[-seed_length:]
# Forecast future latent states
forecasted_latents = engine.forecast_latent(h=forecast_horizon, init_latents=init_latents)
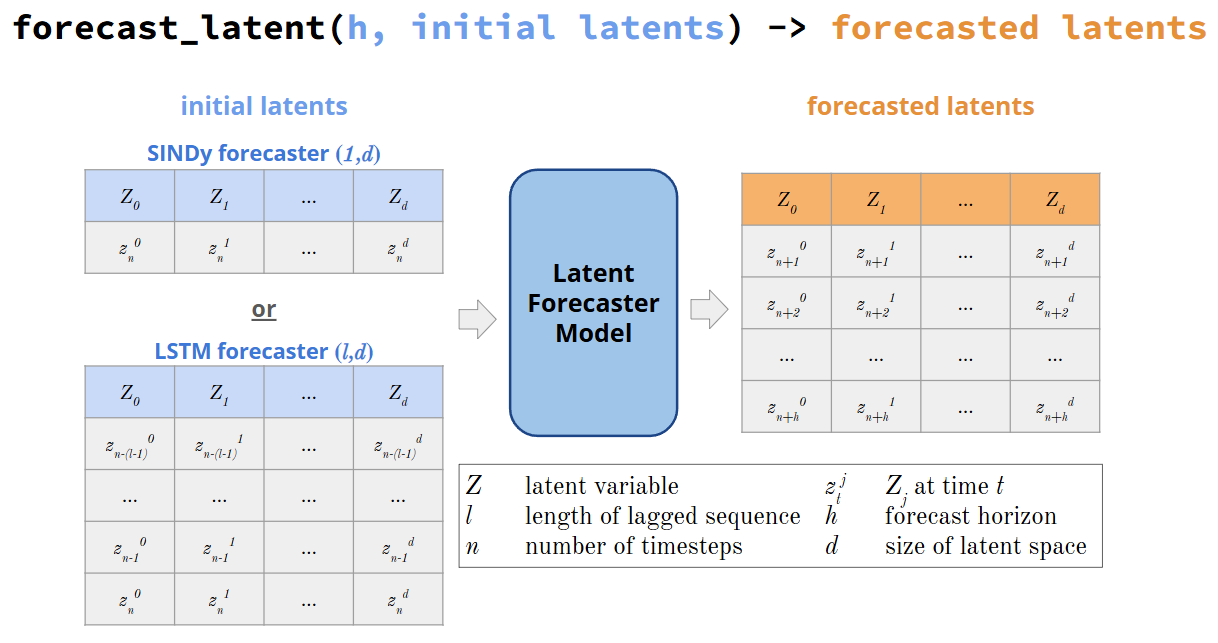
Figure: The forecast_latent method takes in a forecast horizon (number of steps to forecast into the future) and an initial latent space seed. The timesteps requried for the seed depends on SHRED’s latent_forecaster model selected. SINDy_forecaster requires only a single latent space timestep. LSTM_forecaster requires the latent space seed to be of length lags (lags set in LSTM_forecaster). The seed is passed into the SHRED’s latent_forecaster, which then forecasts the latent space h timesteps into the future.#
Decode Latent Space Back to Full-State Space#
The SHREDEngine provides a .decode() method for converting latent representations back into the full-state space.
# Convert latent representations back to full state
full_state_reconstruction = engine.decode(latent_representation)
# You can also decode forecasted latent states
forecasted_full_state = engine.decode(forecasted_latent)
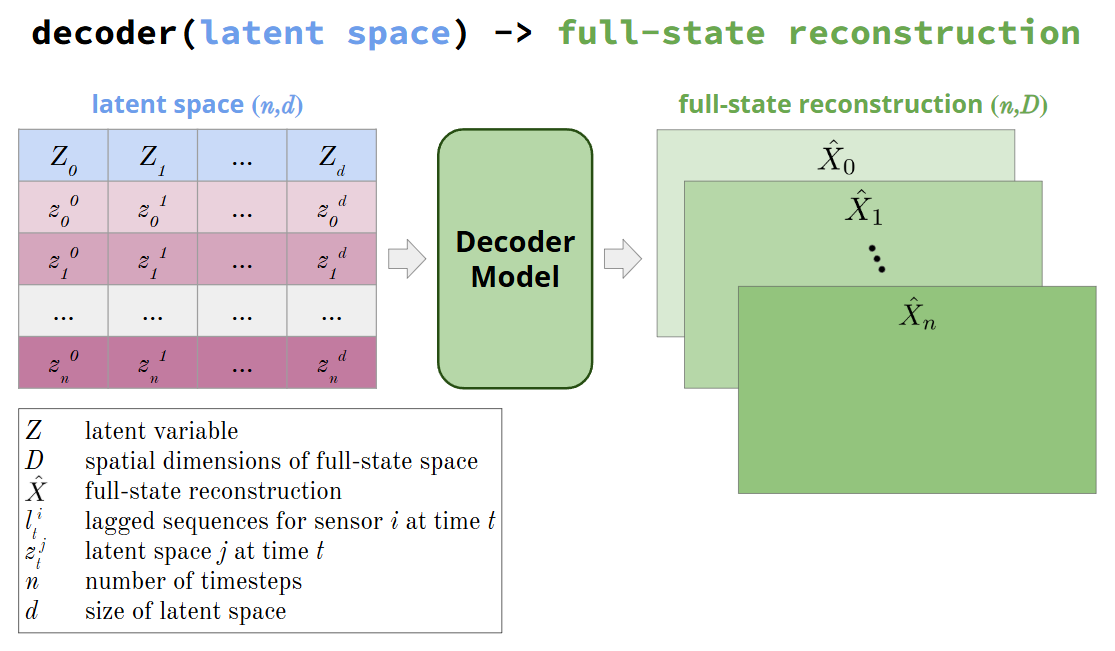
Figure: The decoder method takes in a latent space, passes it through SHRED’s decoder_model, and returns the full-state reconstruction of the latent space.#
Evaluate reconstructions from sensor measurements against ground truth#
The SHREDEngine provides an .evaluate() method that compares reconstructed full-state outputs (from sensor measurements) against the unprocessed ground truth. This method performs end-to-end evaluation in the physical space, automatically handling all necessary post-processing steps.
What the evaluation includes:#
Unscaling: Converts normalized predictions back to original scales using fitted scalers
Decompression: Projects back to full-state space if SVD compression was used during preprocessing
Dataset unstacking: Separates multiple datasets if more than one was added to the DataManager
Metric computation: Calculates comprehensive error metrics (MSE, RMSE, MAE, R²)
Usage example:#
# Prepare ground truth data as a dictionary mapping dataset IDs to arrays
# Each array should have shape (time_steps, *spatial_dimensions)
ground_truth = {
"dataset_1": full_state_data_1, # shape: (T, height, width) for 2D spatial data
"dataset_2": full_state_data_2 # shape: (T, nx, ny, nz) for 3D spatial data
}
# Evaluate model performance
evaluation_results = engine.evaluate(
sensor_measurements=test_sensor_data, # shape: (T, n_sensors)
Y=ground_truth
)
# Display results
print(evaluation_results)
# MSE RMSE MAE R2
# dataset
# dataset_1 0.123 0.351 0.245 0.892
# dataset_2 0.098 0.313 0.198 0.913